

ElevenLabs
The voice-first AI assistant that takes action
A cloud-based software engineering agent that can work on many tasks in parallel, powered by codex-1. Available to ChatGPT Pro, Team, and Enterprise users today, and Plus users soon.
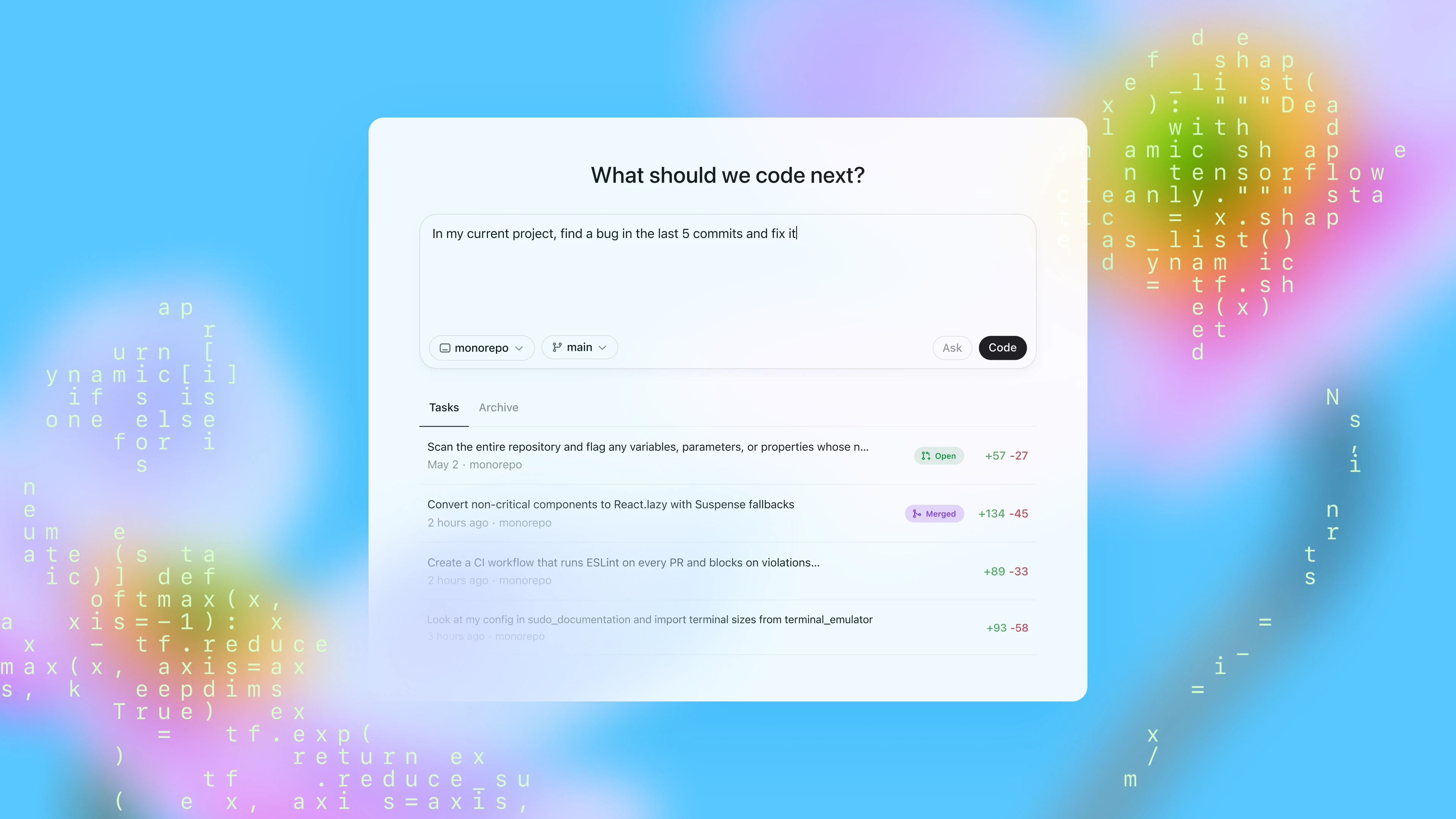
Today we’re launching a research preview of Codex: a cloud-based software engineering agent that can work on many tasks in parallel. Codex can perform tasks for you such as writing features, answering questions about your codebase, fixing bugs, and proposing pull requests for review; each task runs in its own cloud sandbox environment, preloaded with your repository.
Codex is powered by codex-1, a version of OpenAI o3 optimized for software engineering. It was trained using reinforcement learning on real-world coding tasks in a variety of environments to generate code that closely mirrors human style and PR preferences, adheres precisely to instructions, and can iteratively run tests until it receives a passing result. We’re starting to roll out Codex to ChatGPT Pro, Enterprise, and Team users today, with support for Plus and Edu coming soon.
Today you can access Codex through the sidebar in ChatGPT and assign it new coding tasks by typing a prompt and clicking “Code”. If you want to ask Codex a question about your codebase, click “Ask”. Each task is processed independently in a separate, isolated environment preloaded with your codebase. Codex can read and edit files, as well as run commands including test harnesses, linters, and type checkers. Task completion typically takes between 1 and 30 minutes, depending on complexity, and you can monitor Codex’s progress in real time.
Once Codex completes a task, it commits its changes in its environment. Codex provides verifiable evidence of its actions through citations of terminal logs and test outputs, allowing you to trace each step taken during task completion. You can then review the results, request further revisions, open a GitHub pull request, or directly integrate the changes into your local environment. In the product, you can configure the Codex environment to match your real development environment as closely as possible.
Codex can be guided by AGENTS.md files placed within your repository. These are text files, akin to README.md, where you can inform Codex how to navigate your codebase, which commands to run for testing, and how best to adhere to your project’s standard practices. Like human developers, Codex agents perform best when provided with configured dev environments, reliable testing setups, and clear documentation.
On coding evaluations and internal benchmarks, codex-1 shows strong performance even without AGENTS.md files or custom scaffolding.
We’re releasing Codex as a research preview, in line with our iterative deployment strategy. We prioritized security and transparency when designing Codex so users can verify its outputs – a safeguard that grows increasingly more important as AI models handle more complex coding tasks independently and safety considerations evolve. Users can check Codex’s work through citations, terminal logs and test results. When uncertain or faced with test failures, the Codex agent explicitly communicates these issues, enabling users to make informed decisions about how to proceed. It still remains essential for users to manually review and validate all agent-generated code before integration and execution.


A primary goal while training codex-1 was to align outputs closely with human coding preferences and standards. Compared to OpenAI o3, codex-1 consistently produces cleaner patches ready for immediate human review and integration into standard workflows.








